
Hi, On 01/28/2019 10:29 AM, Sebastian Achilles wrote:
I have looked into the Network Performance on CLAIX18. I have measured latency and bandwidth for intra and inter node communication. I have used the Intel IMB PingPong Benchmark complied with the modules intel/19.0 and intelmpi/2019.
Intel MPI 2019 has been told by Intel itself as 'experimental' and is known to show up as inconvenient behavuoiur in some cases. That is why we switched to intelmpi/2018 back after a few days. we recommend to use v2018 and if in doubt compare results to openmpi and/or v2017. (Also v2018 is known to have some issues now.) However, short test of IMB-MPI1 PingPong tell us that v2019 did *not* seem to have a known bandwidth/performance issue compared to older versions.
To get a sufficient statistic I have submitted 64 jobs with 1 node using 2 tasks and 64 jobs with 2 nodes using 1 task each, respectively. The scheduler has started the jobs on different sets of nodes. I have attached the results, showing the configuration and the average, min and max of the measurement.
Let's first look at the inter node communication: I have measured an average latency of 2.12 usec. In the best case I measured 1 usec and in the maximum is 7.1 usec. The bandwidth is on average 6488 Mbytes/sec. The maximum is 11995 Mbytes/sec and minimum is 2483 Mbytes/sec.
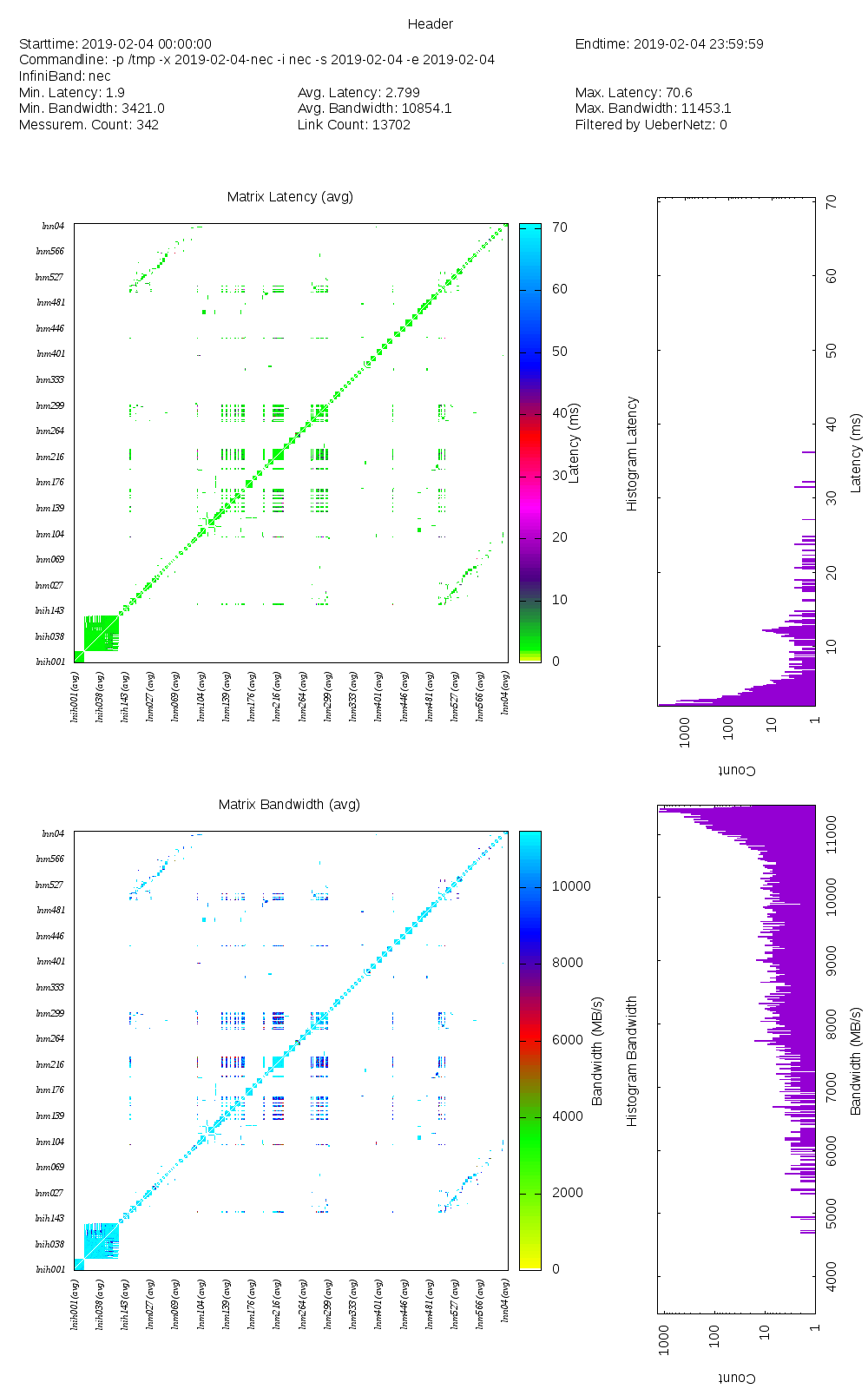
You have to expect some stable 11.5...12.0 GB/s on bandwidth and latency in order of 1...2[usec] on the OmniPath network *when you run on nodes on same leaf switch*, and much worse (quite varyiing with avg about 6GB/s? bandwidth) when running on nodes connected via the thin (upper) switches. Take a look at the attached picture, very characteristic to OPA network of used topology (CLAIX2016 use the same network technology and topolopogy). My assumption is that your multinode pingpong tests run either on non-exclusive nodes (???) or (sometimes) on nodes not at the same leaf switch.
The latency for intra node communication looks okay, however the bandwidth shows variation.
On average theses results don't correspond with the advertised values from Intel. Either I have done something wrong or I haven't understood the topology or there is a problem with the machine.
Have you run such a benchmark as well? Can you observe something similar?
Just try out: pk224850@login18-1:~[506]$ export I_MPI_FABRICS=shm:tmi pk224850@login18-1:~[516]$ $MPIEXEC -m 1 -H login18-1,login18-2 IMB-MPI1 PingPong ... you should get result in order of almost 12GB/s - see below. (Do not repeat this test too often as it loads the front ends. Change to I_MPI_FABRICS is needed ONLY IN INTERACTIVE TESTS as by actual default we failback to DAPL in order to support the (old, Bull) MPI back ends still available now - will ne changed soon. DO NOT CHABGE THIS ENVVAR BY DEFAULT DO NOT CHANGE THIS ENVVAR IN BATCH UNLESS ORDERED ... as this variable control your MPI transport with owerwhelming results to stability and performance. #--------------------------------------------------- # Benchmarking PingPong # #processes = 2 #--------------------------------------------------- #bytes #repetitions t[usec] Mbytes/sec 0 1000 1.12 0.00 1 1000 1.12 0.89 2 1000 1.11 1.79 4 1000 1.11 3.60 8 1000 1.11 7.20 16 1000 1.39 11.53 32 1000 1.39 23.03 64 1000 1.39 46.01 128 1000 1.38 93.02 256 1000 1.38 185.38 512 1000 1.44 356.16 1024 1000 1.61 637.80 2048 1000 1.86 1100.50 4096 1000 2.38 1719.96 8192 1000 3.48 2353.33 16384 1000 7.43 2204.21 32768 1000 9.83 3332.78 65536 640 18.40 3562.04 131072 320 23.82 5503.58 262144 160 33.89 7735.72 524288 80 53.71 9760.96 1048576 40 96.31 10887.26 2097152 20 184.08 11392.80 4194304 10 352.39 11902.29
@Marcus: To get a better understanding of the machine, could you please share a bit more information on the network topology:
- How many levels does the tree have? - On which level is the tree pruned? - Could you send me the connectivity file / connection map, e.g. a list of cables connecting the nodes, edge and core switches? I would like to add the hop count information into my result. (I have a script for computing the hop count from a connection map. Depending on the format I just need to adjust the reading routine)
Cheers, Sebastian
_______________________________________________ claix18-slurm-pilot mailing list -- claix18-slurm-pilot@lists.rwth-aachen.de To unsubscribe send an email to claix18-slurm-pilot-leave@lists.rwth-aachen.de
-- Dipl.-Inform. Paul Kapinos - High Performance Computing, RWTH Aachen University, IT Center Seffenter Weg 23, D 52074 Aachen (Germany) Tel: +49 241/80-24915
{kind=link}